计算效率提升超60倍!杉数科技用GPU芯片开启运筹学新的“大航海时代”
据斯坦福大学报告显示,自2003年以来,GPU性能提高了约7000倍,单位性能价格也提高了5600倍。GPU已经是推动 AI 技术进步的关键动力。

H100 GPU(图片来源:NVIDIA官网)
数周之前,芝加哥大学商学院的鲁海昊教授发现,原本传统依赖英特尔/AMD CPU(中央处理器)芯片进行计算的数学规划求解器(Solver,下称“求解器”),如今却可以突破技术瓶颈。
具体来说,鲁海昊教授团队通过实验发现,求解器能够通过英伟达GPU(图形处理器)和CUDA库函数,设计高效的数学规划算法cuPDLP来求解超大规模问题,并体现出了计算优越性,其研发的cuPDLP软件(Julia版本)也验证了这一点。而该研究成果日前发表在arxiv上。
此后,鲁海昊团队与斯坦福大学博士、杉数科技首席科学家葛冬冬教授团队进行了紧密合作:在最顶级的计算设施,英伟达GPU H100多显卡集群上,团队对自己研发的cuPDLP-C求解软件(C语言版本)进行了实验,验证GPU能否实现线性规划问题求解的“弯道超车”。
钛媒体App获悉,2023年12月8日,杉数科技团队在中国运筹学会算法软件与应用分会成立大会上,报告了他们在英伟达H100 GPU显卡上,成功验证了cuPDLP-C求解超大规模线性规划问题(LP problem)的显著优势。在多个经典测试集上,对于大规模问题,算法体现出了不亚于传统商业求解器的表现,并且在多个大问题上有明显求解优势。
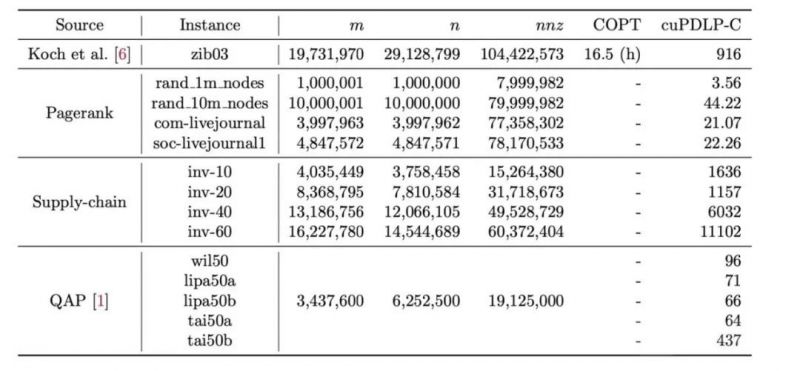
例如,从求解效率来看,领域内著名的测试问题zib03,相比四年前用CPU求解的16.5个小时(用英特尔至强E7-8880 v4),如今在英伟达H100下,cuPDLP-C求解计算时间直接缩短至916秒,时间缩短了64倍。
相较于2009年的CPLEX,计算时间从139天到现在的15分钟,这完全颠覆了数学规划算法设计“只有CPU能做”的传统认知,“降维打击式”地提升了求解计算效率。同时,由于目前cuPDLP-C已经在GitHub上开源,因此整个成果也将让更多人受益。
葛冬冬对钛媒体App表示,“这件事意义重大,它将在未来3-5年对整个运筹学从科研到产业都会产生巨大改变。某种程度上,我认为它将开启一个运筹学科新的‘大航海时代’。”
“有四点对领域的可能冲击吧。首先,这套算法思想推广之后,不仅用在线性系统上,而且对整个连续优化领域都会产生影响,进而深刻影响整数规划计算领域,这对应求解器应用场景中80%的问题;第二,GPU相关的一阶算法设计和执行相对简单,这将使得求解器社区部分模型对应的算法开源化;而专业求解器以后可能跟目前许多toB的AI公司相似,在专业求解和基于GPU的函数定制服务方面都可以发力,带来新的商业机会。第三,求解器会变得更加重视硬件,将需要大量适配的专用高精度计算显卡,以及需要高效的库函数实现。国内很多 AI 芯片也可以应用,形成一个软硬一体化的生态;求解器以后的服务也更可能呈现一个软硬一体化绑定的服务能力。第四,有鉴于求解能力限制,整个运筹学研究的核心之一其实就是如何将大问题分解,分步骤,或者降维求解,而随着GPU求解算法的‘暴力’求解大问题能力剧增,可以预期运筹学领域,也包括相关的多个商科和工科领域的科研范式和产业形态也将随之极大改变,甚至重塑。”葛冬冬告诉钛媒体App。
很显然,通过GPU显卡的算力加持,对已经发展70余年、古老且严谨的运筹学科将会带来革命性的冲击。
计算时间缩短超过64倍,GPU芯片将加速求解更多复杂问题
运筹学是近代应用数学的一个分支,主要是研究如何将生产、管理等事件中出现的优化问题加以提炼,然后利用数学方法进行解决的学科。
美国物理学家,曾任加州大学柏克莱分校教授的Charles Kittel早在1947年首次提到“Operations Research”一词,中国则在1957年由中国工程院院士许国志、清华大学基础科部教授周华章正式定名为“运筹学”,并于1980年成立中国运筹学会(ORSC)。运筹学在全球发展至今已超过70年。
其中,数学规划是将现实问题转化为数学模型并求解的过程。数学规划求解器作为这一过程的核心软件,专门针对多种线性、整数和非线性规划模型进行算法优化。它可以被视为一个“黑盒子”系统,业界亦称之为算法领域的“芯片”。
求解器的重要意义在于,它能解决生活中非常复杂的应用数学问题。例如,2018年平昌冬奥会的闭幕式上,中国接棒八分钟展示里出现的无人仓机器人引起全球关注。但如何计算这些机器人的运行路线,为了确保这些机器人运行高效且避免碰撞,需要依赖最优算法,而背后依靠的就是求解器。
在此之前,求解器的核心计算硬件大部分依赖于CPU(中央处理器)芯片,主要原因是CPU的通用能力可以更广泛应用于众多计算系统和 算法实现,而且英特尔、AMD相关软件框架都非常齐全,特别是复杂高精度的各种矩阵运算,大大降低求解规划成本,并提高计算效能。
葛冬冬指出,芯片这类硬件是求解器底层的核心设施。
长期以来,GPU采用与CPU不同的底层架构,计算核心数量、软件和性能处理方案与CPU的底层逻辑差异极大。而国内外科研人员希望能够通过GPU或是其他类型芯片可实现线性规划的加速计算,但多次实验结果显示,GPU一直无法高效求解算法中的“矩阵求逆”或者“矩阵分解“问题,无论是计算精度(物理原因)还是并行计算,它都无法做到。
“未能突破的原因是,求解器的核心底层只要是这种连续优化问题,不管是线性还是非线性,传统算法中都躲不开如何高效求解‘矩阵分解’这一步。这个问题解决不了,GPU几千个计算单元并行加速的优势就无法体现。”葛冬冬对钛媒体App表示,“矩阵分解”主要对应线性方程组求解,是计算最关键一步。一旦矩阵规模过大或者结构复杂,这个步骤往往会造成内存溢出或者求解时间极长,成为求解桎梏。

杉数科技首席科学家葛冬冬教授
早在2016年,葛冬冬联合几位当年在斯坦福的博士同学,共同成立了杉数科技,研制了第一个国产专业求解器,避免受制于人。如今,作为智能决策技术服务公司,杉数科技以其自研大规模商用求解器COPT为核心引擎,打造了“计算引擎+决策技术中台+业务场景”的端到端智能决策技术平台,为消费零售、交通物流、能源电网、制造与供应链等多个行业提供数字化供应链解决方案,利用运筹优化和机器学习找出更优的决策方案,全面提升产业链和供应链运营效率和效果。
葛冬冬此前向钛媒体App透露,利用COPT数学优化求解器这种优化决策,可以使生产排程订单满足率提高20%,产能损失率降低30%,排产排程人工干预降低70%,非计划维修降低15%。同时,杉数科技COPT数学优化求解器一直在全球求解器榜单中名列前茅。
而此前葛冬冬团队研发的COPT求解器系列,主要是利用CPU芯片进行计算处理的。
“事实上,过去十几年,这个领域内,包括我们,国内外学术界无数人,都在前赴后继地努力,试图回答这个问题:GPU/CUDA架构能否对数学规划求解器起到弯道超车的作用。此前的答案一直为‘否’。”葛冬冬表示。
然而,2023年11月初,葛冬冬的合作伙伴,鲁海昊教授在arXiv上发表了一篇论文,他们公开的cuPDLP代码,通过GPU硬件成功解决了线性规划求解计算问题,可用在这段Julia代码中求解线性规划。
葛冬冬说:“鲁老师突破这一长期瓶颈的技术方案,是他们观察到以前的CPU/GPU混合架构求解中,CPU/GPU之间的交互往往占用了绝大部分耗时,因此他们在此前他们与谷歌合作建立的PDLP求解器基础上(此求解器可以很好解决GPU计算精度无法达到10^-8精度要求的限制),将整套算法搬到了GPU/CUDA架构下实现。捅破了最后一层窗户纸!
此后,鲁教授与葛冬冬教授领导的杉数COPT团队紧密合作,提出开源技术方案cuPDLP-C,即用一阶方法在GPU上解决线性规划问题,也是Julia版本cuPDLP.jl的C语言加强版,算法上也做了进一步的改善和提高。
与此同时,通过在目前最强的显卡H100上的实验发现,在运筹学最经典的测试集MIPLIB2017的383个线性松弛测试问题求解中,以10^-4 精度要求,cuPDLP-C已经可以求解到379个问题,而以严格收敛的标准10^-8 精度要求,cuPDLP-C也可以求解到369个问题。总体求解时间与目前最好的商业求解器的差距也拉近到了2倍(10^-4精度)和6倍(10^-8)精度之内。在测试集那些大问题中的差距明显更小,在10^-4精度下甚至体现出了计算优势。此外,葛冬冬团队还在多个更大规模问题上进行了广泛测试,cuPDLP-C的优势明显,例如zib03问题加速了64倍,而多个更大规模的测试问题,如在谷歌的Pagerank、某国内大企业供应链项目问题、经典的二次分配问题(QAP)等问题的测试上,传统求解器都无法求解,而cuPDLP-C可以做到可行时间内求解。
很显然,对于超大数学规划问题,在性能、计算速度、求解数量等方面,GPU都能比CPU都展现出了更好的前景。
杉数科技资深副总裁,技术负责人皇甫博士对钛媒体App表示,利用GPU硬件,现在cuPDLP-C可以让之前难以解决的大规模优化问题变得易于解决,推动了模型建立的精确度和规模。以前因CPU限制而采用的非常精密复杂的一些求解技巧可能不再需要。此外,一旦GPU提速上百倍,cuPDLP-C求解优势可能拓展到其他连续优化领域,极大加速求解过程,让原本耗时的问题快速得到解决,从而打开新的应用可能性。
葛冬冬告诉钛媒体App,“这很恐怖。对于运筹学来说,这一技术意外打破了一个长期以来的定论,即GPU在求解数学规划问题上没什么加速效果。这一发现会让整个学术和工业界感到惊讶,因为之前从未有人预料到这种情况。”
他强调,cuPDLP-C技术推翻了运筹学科长期以来的一些共识和定式,超出人们预期,利用GPU提高了求解器的性能潜力,可能使运筹学实现从CPU到GPU计算带来的“范式转变”。
目前,cuPDLP-C技术代码已经开源,相关论文也已经公开发表在arXiv上。GitHub地址:
https://github.com/COPT-Public/cuPDLP-C
20年性能提高约7000倍,GPU成本过高是否将制约行业发展?
过去一年,以ChatGPT为代表的生成式 AI 技术风靡全球。而作为以95%的市场占有率垄断了全球 Al 训练芯片的英伟达,成为了这轮 AI 混战的最大赢家,其研发的A100/A800、H100/H800等多款 AI 芯片成为 AI 热潮中的“爆品”。
正如英伟达自己所说:“GPU 已经成为人工智能的稀有金属,甚至是黄金,因为它们是当今生成式 AI 时代的基础。”
从技术角度来说,GPU优于CPU,特别是在并行计算能力、能耗效率和CUDA生态等方面,它的高算力和可扩展性使英伟达GPU成为AI加速芯片市场的首选。
根据斯坦福大学最近发布的一项报告显示,自2003年以来,GPU性能提高了约7000倍,单位性能价格也提高了5600倍。该报告还指出,GPU是推动 AI 技术进步的关键动力。
英伟达首席科学家Bill Dally也曾表示,NVIDIA GPU在过去十年中将 AI 推理性能提高了1000倍。
从运筹学角度来看,将CPU替换为GPU,计算能力、计算效率大幅提升。但问题在于,国内可以买到的H100/H800、A100/A800的价格都已经超过20万/张,再加上存储、NVLink互连、运维成本等,相比CPU,基于GPU的求解成本将进一步攀高。
那么,求解计算的基础设施成本,是否会成为未来求解器乃至运筹学发展的重要制约因素?
葛冬冬对钛媒体App表示,目前只是基于GPU架构的优化算法的“拓荒期”。目前,他们已经与多家国产 GPU芯片厂商开展了广泛的测试合作,希望能够利用国产算力推动中国求解器行业发展。确实有部份国产GPU芯片已经具备了跑通算法的能力,但是也确实,还需要在芯片速度和库函数完备程度上做进一步建设。
而且,他认为,杉数也已经积极与商业伙伴开始积极探索这一技术的落地与应用前景。目前已经开始在电力系统的出清调度问题这一大规模复杂系统问题上,与南网总调合作,探寻运用GPU架构的优化求解算法来加速求解计算的研究。
谈及开源与商业化的话题,葛冬冬认为,把cuPDLP-C开源可以推动行业进一步发展,对于商业化求解器来说肯定会有一定冲击,但GPU求解大规模问题的新思路也带来了巨大的机会,目前来看,杉数科技在核心技术、商业化等层面还有非常领先的市场竞争优势。
“新的大门已经推开。过去20年,大家一直在尝试推开,但门被‘锁’死了。现在等于是发现‘锁’能打碎,门是能推开的。这就意味着运筹学算法又进入了一个新的‘大航海时代’,一个堪比‘西部掘金热’的时代。我们已经走出(开源)这一步。我们对自己的技术有信心,过去七年,从无到有,再到国际领先,杉数一直都在科研、技术和实践应用上,是国内求解器市场的领航者。在这个经我们的手打开的新时代,我相信,我们是不会落后的。”葛冬冬表示。
声明:本站作为信息内容发布平台,页面展示内容的目的在于传播更多信息,不代表本站立场;本站不提供金融投资服务,所提供的内容不构成投资建议。如您浏览本站或通过本站进入第三方网站进行金融投资行为,由此产生的财务损失,本站不承担任何经济和法律责任。 市场有风险,投资需谨慎。同时,如果您在中国发展网上发现归属您的文字、图片等创作作品被我们使用,表示我们在使用时未能联系到您获取授权,请与我们联系。
【本文资讯为广告信息,不代表本网立场】