YOCSEF 深圳举办Wiztalk·湾区会议第二期,共探大模型前沿与未来
8月26日,YOCSEF 深圳“Wiztalk.湾区会议”特别品牌活动第二期研讨会顺利举行。活动聚焦“大模型前沿技术与发展趋势”,让与会嘉宾从不同角度讨论思辨,尝试在大模型未来发展领域探寻新的方向。YOCSEF深圳老主席陈小军和现任AC寇立言作为执行主席。

与会人员合影

陈小军主持
会议伊始,陈小军向来自香港高校和企业界的嘉宾们简要介绍了CCF YOCSEF的文化以及“Wiztalk·湾区会议”系列活动的定位。深圳大学特聘教授黄哲学、深圳大学大数据系统计算技术国家工程实验室副主任沈琳琳、香港科技大学(广州)信息枢纽终生教授王炜、中山大学(深圳)副教授/国家级青年人才梁小丹、香港中文大学的孔秋强等受邀报告嘉宾;哈尔滨工业大学(深圳)副教授户保田、香港大学助理教授黄超、微众银行范涛、深圳数据交易所王吴越受邀做议题引导嘉宾;北京交通大学教授\YOCSEF总部AC金一、YOCSEF深圳2013-2014主席\CCF深圳监委\清华大学深圳研究生院教授袁春、北京交通大学教授魏云超、深圳大学教授吴晓晓\特聘教授秦建斌、北京大学深圳研究生院助理教授袁粒、幂商科技余冰、香港生产力促进局成杰峰等受邀参加会议。
今年初, ChatGPT火爆全网,接着各大公司及开源社区推出了各种大模型,竞争激烈,然而目前大模型在理论及落地上还存在许多问题。

袁春和金一致辞
会上,YOCSEF深圳2013-2014主席、CCF深圳监委、清华大学深圳研究生院教授袁春,以及YOCSEF总部AC/北京交通大学教授金一首先做了致辞。
本次活动分为两个专题,大模型专题及大数据专题。
Part1,大模型专题:
沈琳琳以《AIGC之伶荔中文大语言模型》为题,介绍了自研的TencentPretrain框架,以及基于此框架对LLaMA微调得到的伶荔大模型。
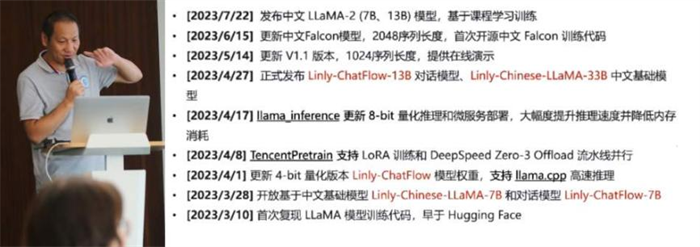
伶荔中文大语言模型发展路径
梁小丹做了《多模态开放域检测大模型及应用》报告,介绍了团队在语言-视觉大模型方面的工作,并将其用于机器人导航上取得了不错的效果。

孔秋强以《大语言模型在音频信号处理中的应用与展望》为题介绍了音频信号处理的经典任务,探讨了大模型时代音频信号处理的新数据集、新模型、新任务,以及音频领域的理解和生成任务的难点。
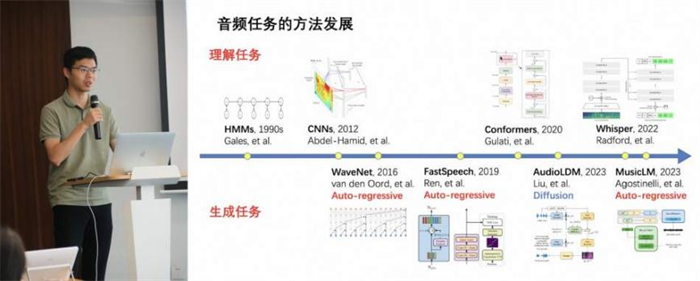
在大模型专题的思辨环节,嘉宾们就大模型演进及落地的技术路径进行了深度思辨。
首先是针对大模型的技术架构问题,讨论了两个子问题。
1)尽管目前常用的Transformer架构具有计算高效、上下文感知等优点,但也存在如训练数据量要求高、可解释差、学习长距离依赖关系的能力有限及推理速度慢等缺点。所以,未来是沿用现有的Transformer架构还是探索新的架构?王炜表示Transformer在基础理论及计算成本等方面存在较大的问题,孔秋强也表示其难以处理音频数据中的长序列问题。余冰表示,在工业界,现有架构推理速度慢影响了效率。清华大学袁春指出可以使用量化、剪枝及蒸馏等方法来加快大模型的推理速度。户保田表示从零开始学习多模态大模型比较困难,更实用的方式是利用已有的大语言模型来对视觉信息进行对齐。袁粒表示,训练数据及指令数据的质量对大模型的性能影响值得关注。深圳大学特聘教授黄哲学表示,需要结合经典的统计学习来改进现有的大模型技术。
2)针对领域大模型,从头开始训练不大实际,所以目前大都利用已有的大语言模型进行微调。但微调的多模态大模型性能有限,所以需要探索新的路径。针对该问题,余冰表示,通用大模型需要和行业知识图谱进行结合,利用行业知识图谱来对大模型进行微调。梁小丹表示某些实际应用需要大模型有自我纠正的能力,能及时发现错误并修正。魏云超相比于微调利用大模型+知识库的方式更加有效。
其次是探讨了大模型落地的技术架构问题。
1)在实际应用场景中,是应该选择大模型、小模型组合还是大小模型协同?孔秋强表示,工业界的语音识别等应用,更乐意采用小模型组合的方式。但余冰指出语音任务最好是训练通用的大模型,并在此基础上增加对其他语言的支持。户保田提出可以利用多个小模型去解决传统大模型才能解决的复杂问题。魏云超和袁春都表示,在视觉任务上大模型是一种趋势。梁小丹表示由于基础的视觉模型能力的增强,机器人的模型体系已经从端到端优化变为固定一些模型来优化其他模型。
2)大小模型如何协同进化?梁小丹建议可以将小模型作为agent,通过大模型来组合小模型以协同进化。不过袁春表示即使在自动驾驶场景,感知和决策也很难合在一起来做。
经过一上午的激情研讨,初步达成了如下共识:目前Transformer推理速度慢问题严重,需要探索新的架构,并关注训练数据的质量。针对领域大模型,通用大模型+行业知识图谱成为大方向,需要结合连续学习的方式来对大模型的知识进行更新。
Part2,大数据专题:
下午,两位重量级的嘉宾带来新的分享。
黄哲学以《非MapReduce大数据计算》为题,介绍了与传统的全量数据计算不一样的随机样本计算技术,指出通过对数据进行打乱抽样,在少量随机样本而不是全量数据上进行近似计算,可以获得非常高的性能加速并极大地降低大数据的处理成本。

香港科技大学(广州)王炜以《Towards Understanding the "Intelligence" of Large Language Models》为题探讨了大语言模型的智能涌现机制、局限性,介绍了大模型编辑及蒸馏方面的一些工作,并指出了一些大语言模型未来重要的研究问题,如大语言模型的机制及更多的能力、快速知识更新等。

在大数据专题的思辨环节,嘉宾们就大模型和大数据技术如何结合进行了深度思辨。
首先探讨了大模型对数据的需求问题。针对大模型的训练数据缺乏问题,余冰表示可以利用种子数据来合成所需的数据。吴晓晓表示数据集要考虑公平问题,以避免数据偏见被引入大模型中,并考虑大模型的价值观问题。王吴越表示数据隐私问题可以通过一次授权、多次使用来解决数据多次授权的效率问题。黄哲学表示,大模型训练数据的清洗成本和冗余性比较高,可以将大数据划分后进行清洗,同时利用统计技术对数据去冗余,以降低开销。王炜也提出在实际应用中,可以考虑对数据进行压缩,同时,如何评估数据对自身的价值以制定合适的价格至关重要。袁春提出可以用元学习的方法来解决大模型数据缺乏的问题。
接着讨论了大模型时代,大数据技术的发展趋势。王炜表示在25年,前数据库的学者就有一个愿望,希望能实现对多种数据的管理,现在可以尝试解决大规模/多模态数据的数据质量及数据管理问题。袁春说可以将知识用文本的方式描述出来,方便人们的理解。黄哲学表示大模型不是万能的,要对大模型的输出做好评估及控制以避免严重后果。余冰表示在工业大数据领域,要考虑安全数据的边界。成杰峰则看好大模型和大数据管理技术的深度结合。
经过一下午的激烈辩论,达成了新的共识,即:数据交易可以解决大模型的数据问题,数据压缩、数据合成及元学习是有效的解决训练数据不足的技术手段。同时,利用大模型来提升大数据清洗、管理、检索、推荐是大模型时代大数据技术的重要发展趋势。
经过嘉宾们的反复讨论,对大数据模型前沿技术与发展趋势有了新的见解,希望通过本次讨论能形成若干有意义的共识,使相关领域从业人员受益。
声明:本站作为信息内容发布平台,页面展示内容的目的在于传播更多信息,不代表本站立场;本站不提供金融投资服务,所提供的内容不构成投资建议。如您浏览本站或通过本站进入第三方网站进行金融投资行为,由此产生的财务损失,本站不承担任何经济和法律责任。 市场有风险,投资需谨慎。同时,如果您在中国发展网上发现归属您的文字、图片等创作作品被我们使用,表示我们在使用时未能联系到您获取授权,请与我们联系。
【本文资讯为广告信息,不代表本网立场】