存储必须更懂业务和场景
中国经济导报、中国发展网 记者崔立勇报道
“存储是在最底层的基础和关键。”中科曙光存储科技有限公司总裁何振日前在接受本报记者采访时表示,存储是数据基础设施的重要部分,如果发生风险,各类应用就会随之出现问题,数据丢失更是不能接受的。
数字经济蓬勃发展,当数据创造出巨大价值的时候,存储的重要性日益凸显。何振说,虽然用户对存储的直接感知不多,但是身处“背后”的强性能、高可靠、易管理的智能化存储底座至关重要。

向覆盖全行业全场景努力
“没有一个通用设备可以一成不变地长期支持用户的业务发展。”深入业内多年的何振有着深切的感受——存力平台必须场景化,存力必须和用户的业务场景紧密结合起来。
中科曙光存储科技有限公司副总裁张新凤分析,不同行业、不同场景对存储的功能需求存在差异,对存储性能指标的要求也完全不同。只有深耕行业,才能解决用户在不同业务场景下的痛点。
从为大型算力中心做存储的配套服务,到逐渐向各个通用场景推进,曙光存储已经在电信运营商、AI、医疗、金融、政府、能源、制造等多个领域获得突破。
张新凤举例,在自动驾驶领域,曙光存储和应用伙伴一起,给自动驾驶的企业提供符合安全监管、性能更优的数据处理平台解决方案。与之类似,在通信、气象、石油等领域,曙光存储也在努力将自身的技术优势和行业的应用深度绑定,通过代码级的深度优化来支撑业务。
针对不同的应用场景,曙光存储的解决方案团队首先要充分理解应用场景,然后根据用户特定需求完成架构方案。“这个阶段拼的是综合实力。”何振说,近期曙光存储受到自动驾驶和国内AI大模型的青睐,原因就在于曙光存储可以根据用户需求灵活调整,优化性能,将存储价值更加充分地发挥出来。
因为曙光存储在产品研发之路上已经率先走过艰苦的一段,所以在“最后一公里”就变得相对容易。“从第一行代码开始,都是自研的。”何振表示,正因为曙光存储的产品是自研完成,所以面对不同行业的定制化需求时,响应就主动而快速。
“曙光存储将向覆盖全行业全场景努力。”何振表示,存力平台更懂业务是发展趋势,只有实现这一目标才能在行业中保持竞争力。
一行一行代码去研发
中科曙光总裁历军在曙光存储的新品暨品牌发布会上表示:“新技术新应用快速迭代,而算力和存力是不变的两大底层支撑,先进算力和先进存力也是曙光长期投入研发的重要业务之一。”
曙光存储是中科曙光自主开发的第二大产品线。从最早的5名工程师发展到上千人规模的团队,成为国内存储行业的领头羊,拥有多个领先业界的自研存储产品,曙光存储走过了整整二十年的奋斗历程。
“一行一行代码去研发,一行一行地去优化。”何振表示,从底层代码直到各类应用产品上市,曙光存储始终坚持全栈自研。
曙光存储为什么不选择更加短平快的路径?面对行业的疑问,何振表示,这源自企业的基因——中科曙光一路坎坷一路过关斩将,攻坚克难,多年来一一解决卡脖子难题,站在了国家信息技术产业的最前列。
曙光存储日前推出了完全具有自主知识产权的全球首个亿级IOPS集中式全闪存储FlashNexus。这不仅是全球首个亿级IOPS集中式全闪存储,还是业界唯一有百控级扩展能力的集中式存储产品,稳定性保障首次突破7个9,综合性能领先同类产品50%以上。

曙光存储“强存”——重磅发布FlashNexus集中式全闪新品
成为“更懂AI”的存储
AI大模型蓬勃发展,随之而来的根本诉求是将GPU等芯片的资源效率充分发挥出来——在训练和推理的过程中,存储跑得更快,让前端的计算资源不等待,并确保整个过程中数据的安全可靠。
张新凤表示,随着AI技术的发展,大模型发展非常迅速,参数从百亿计到千亿计甚至万亿级别。AI应用对存储的要求不止于量的增加。她进一步分析,在AI大模型开发中,训练阶段和推理阶段对存储的要求并不一样。训练阶段标准更高,一般是先对数据集完成初步的清理,再导入存储和显卡。在这个数据加载的过程中,业界碰到的最大难题是加载的小文件数量庞大。很多训练依靠大量100K左右的文本和图片。对存储来说,传输大量小文件的速度远比传输一个大文件慢,当千万数量的KB级小文件集中出现,提高加载速度就成为难题。
张新凤介绍,针对这些AI需求,曙光存储拿出了一套“办法”:为用户提供强性能的全闪存储,实现端到端的NVMe全闪的技术优化;分布式存储升级以后成为“更懂AI”的存储,根据AI应用的特点将存储和应用融合起来,利用更多级缓冲的加速机制,进一步把I/O的时间缩短;第三,通过自有的液冷技术,在绿色节能方面为AI应用赋能。
张新凤所说的升级是指曙光推出了新一代ParaStor分布式全闪存储,全平台性能提升超过20倍,单节点带宽最高达到130GB/s,320万IOPS,成为国产化、x86、ARM等平台的理想选择。作为AI存储加速利器,升级后的ParaStor全闪存储具备五级数据加速技术,包括本地内存加速、BurstBuffer加速层、XDS双栈兼容、网络加速与存储节点高速层,搭配全路径AI亲和机制,让数据无需等待。

曙光存储“智存”——ParaStor分布式全闪系列全面升级
让数据流动起来
何振分析,存储行业在此前两年处于低潮期。2024年,整个市场行情开始上升。他认为,市场需求的增加一方面来自AI大模型、自动驾驶等对存储的刚性需求,另一方面企业数字化转型进入关键阶段,对存储需求增多。
“从上半年的市场表现分析,今年存储行业的表现将比去年好很多。”何振告诉记者,过去两三年,各地掀起了建设智算中心的热潮,很多企业购置了大量GPU、服务器等产品,与此同时存储常常被忽视。智算中心建成后,首要问题就是补上存储的欠账,让存力和算力配套起来。
曙光存储的产品集中于分布式和超融合,曙光存储最新发布的FlashNexus系列补齐了集中式全闪产品的产品线。据介绍,在我国的分布式存储、超融合和集中式存储三类中,集中式存储占比超过50%。推出集中式存储产品,意味着曙光存储将进入另一半存储市场,由此打开新局面。
张新凤解释,集中式存储和分布式存储是相辅相成的关系,两者长期共存,不会出现彼此的简单取代。她说,集中式存储拓展能力相对较低,但是凭借高性能、高可靠性、低延迟的优势,获得了金融、医疗等行业的青睐,目前集中式存储在国外的占比也更高,而AI对存储的大部分需求指向分布式存储。
“让数据流动起来。”张新凤表示,用户的数据开始或放在集中式存储上,或放在分布式存储上,但是伴随各类应用的发展,两个地方的数据必须集中起来,以便进一步分析挖掘。
张新凤解释,将集中式和分布式的数据汇聚到一个设备的过程将遇到新的问题,跨域存储集群组合管理、数据冷热分级感知、数据跨域网流动及跨域无感知访问等关键技术亟待攻克。传统的解决方法包括将集中式的数据通过应用层缓慢地拷贝到分布式上面。
集中式和分布式两大存储模式之间的障碍已经被曙光存储打通。曙光存储首创“通存”解决方案,借助同根同源的集中式存储资源池与分布式存储资源池,让数据无界流动,实现跨平台一键式容灾恢复、跨形态热温冷数据无感流动和跨域资源池全维度视图。当拥有了将集中式和分布式打通的技术,就可以在存储层完成这项工作,充分提升存储资源利用率,大大减轻了用户后续系统升级包括数据汇集的难题。
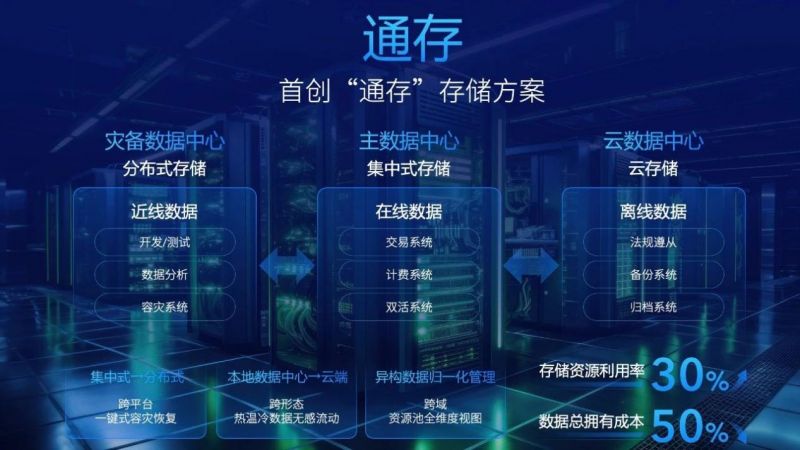
曙光存储首创“通存“方案
“以前是将数据流动的工作留给用户,现在基本上不需要用户费心,用户可以把问题交给曙光存储来解决。”张新凤说。
相信通过像曙光存储这样的国产企业的技术突破和业务崛起,中国存力将再上一个台阶,助力中国企业迎接更光明的AI时代!
责任编辑:崔立勇